Работа с Google Cloud Platform (compute target pool) и Terraform в Unix/Linux
Google Cloud Platrorm — это платформа вида «инфраструктура как сервис» (IaaS), позволяющая клиентам создавать, тестировать и развертывать собственные приложения на инфраструктуре Google, в высокопроизводительных виртуальных машинах.
Google Compute Engine предоставляет виртуальные машины, работающие в инновационных центрах обработки данных Google и всемирной сети.
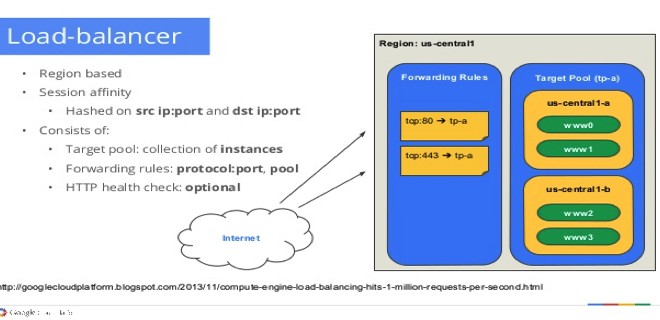
Compute target pool — определяет группу экземпляров, которые должны получать входящий трафик от форвординг-правил. Когда форвординг-рул направляет трафик в target-pool, Google Compute Engine выбирает ноду из этих таргет-пулов на основе хэша исходного IP-адреса и порта, а также IP-адреса и порта назначения.
Установка terraform в Unix/Linux
Установка крайне примитивная и я описал как это можно сделать тут:
Установка terraform в Unix/Linux
Вот еще полезные статьи по GCP + Terrafrom:
Работа с Google Cloud Platform (compute instance) и Terraform в Unix/Linux
Работа с Google Cloud Platform (compute health check) и Terraform в Unix/Linux
Так же, в данной статье, я создал скрипт для автоматической установки данного ПО. Он был протестирован на CentOS 6/7, Debian 8 и на Mac OS X. Все работает должным образом!
Чтобы получить помощь по использованию команд, выполните:
$ terraform --help
Usage: terraform [--version] [--help] <command> [args]
The available commands for execution are listed below.
The most common, useful commands are shown first, followed by
less common or more advanced commands. If you're just getting
started with Terraform, stick with the common commands. For the
other commands, please read the help and docs before usage.
Common commands:
apply Builds or changes infrastructure
console Interactive console for Terraform interpolations
destroy Destroy Terraform-managed infrastructure
env Workspace management
fmt Rewrites config files to canonical format
get Download and install modules for the configuration
graph Create a visual graph of Terraform resources
import Import existing infrastructure into Terraform
init Initialize a Terraform working directory
output Read an output from a state file
plan Generate and show an execution plan
providers Prints a tree of the providers used in the configuration
push Upload this Terraform module to Atlas to run
refresh Update local state file against real resources
show Inspect Terraform state or plan
taint Manually mark a resource for recreation
untaint Manually unmark a resource as tainted
validate Validates the Terraform files
version Prints the Terraform version
workspace Workspace management
All other commands:
debug Debug output management (experimental)
force-unlock Manually unlock the terraform state
state Advanced state management
Приступим к использованию!
Работа с Google Cloud Platform (compute target pool) и Terraform в Unix/Linux
Первое что нужно сделать — это настроить «Cloud Identity». С помощью сервиса Google Cloud Identity вы сможете предоставлять доменам, пользователям и аккаунтам в организации доступ к ресурсам Cloud, а также централизованно управлять пользователями и группами через консоль администратора Google.
Полезное чтиво:
Установка Google Cloud SDK/gcloud в Unix/Linux
Еще ссылки на GCP + Terraform:
Работа с Google Cloud Platform (compute instance) и Terraform в Unix/Linux
Работа с Google Cloud Platform (compute health check) и Terraform в Unix/Linux
У меня есть папка terraform, в ней у меня будут лежать провайдеры с которыми я буду работать. Т.к в этом примере я буду использовать google_cloud_platform, то создам данную папку и перейду в нее. Далее, в этой папке, стоит создать:
$ mkdir examples modules
В папке examples, я буду хранить так званые «плейбуки» для разварачивания различных служб, например — zabbix-server, grafana, web-серверы и так далее. В modules директории, я буду хранить все необходимые модули.
Начнем писать модуль, но для этой задачи, я создам папку:
$ mkdir modules/compute_target_pool
Переходим в нее:
$ cd modules/compute_target_pool
Открываем файл:
$ vim compute_target_pool.tf
В данный файл, вставляем:
#---------------------------------------------------
# Create compute target pool
#---------------------------------------------------
resource "google_compute_target_pool" "compute_target_pool" {
count = "${!var.use_compute_target_pool_default ? 1 : 0}"
name = "${lower(var.name)}-tp-${lower(var.environment)}"
description = "${var.description}"
project = "${var.project}"
region = "${var.region}"
instances = ["${var.instances}"]
health_checks = ["${var.health_checks}"]
backup_pool = "${var.backup_pool}"
failover_ratio = "${var.failover_ratio}"
session_affinity = "${var.session_affinity}"
}
resource "google_compute_target_pool" "compute_target_pool_default" {
count = "${var.use_compute_target_pool_default ? 1 : 0}"
name = "${lower(var.name)}-tp-${lower(var.environment)}"
description = "${var.description}"
project = "${var.project}"
region = "${var.region}"
health_checks = ["${var.health_checks}"]
backup_pool = "${var.backup_pool}"
failover_ratio = "${var.failover_ratio}"
session_affinity = "${var.session_affinity}"
}
Открываем файл:
$ vim variables.tf
И прописываем:
variable "name" {
description = "A unique name for the resource, required by GCE. Changing this forces a new resource to be created."
default = "TEST"
}
variable "project" {
description = "The project in which the resource belongs. If it is not provided, the provider project is used."
default = ""
}
variable "region" {
description = "Where the target pool resides. Defaults to project region."
default = ""
}
variable "environment" {
description = "Environment for service"
default = "STAGE"
}
variable "backup_pool" {
description = "URL to the backup target pool. Must also set failover_ratio."
default = ""
}
variable "description" {
description = "Textual description field."
default = ""
}
variable "failover_ratio" {
description = "Ratio (0 to 1) of failed nodes before using the backup pool (which must also be set)."
default = 0
}
variable "health_checks" {
description = "(Optional) List of zero or one health check name or self_link. Only legacy google_compute_http_health_check is supported."
#type = "list"
default = []
}
variable "instances" {
description = "List of instances in the pool. They can be given as URLs, or in the form of 'zone/name'. Note that the instances need not exist at the time of target pool creation, so there is no need to use the Terraform interpolators to create a dependency on the instances from the target pool."
#type = "list"
default = []
}
variable "session_affinity" {
description = "How to distribute load. Options are 'NONE' (no affinity). 'CLIENT_IP' (hash of the source/dest addresses / ports), and 'CLIENT_IP_PROTO' also includes the protocol (default 'NONE')."
default = "NONE"
}
variable "use_compute_target_pool_default" {
description = "Enable compute target pool default for compute autoscaler or compute instance group manager. Default - fasle"
default = false
}
Собственно в этом файле храняться все переменные. Спасибо кэп!
Открываем последний файл:
$ vim outputs.tf
И в него вставить нужно следующие строки:
output "self_link" {
description = "self link for target pool"
value = "${google_compute_target_pool.compute_target_pool.*.self_link}"
}
output "name" {
description = "Name of target pool"
value = "${google_compute_target_pool.compute_target_pool.*.name}"
}
output "default_pool_name" {
description = "Name for default target pool"
value = "${google_compute_target_pool.compute_target_pool_default.*.name}"
}
output "default_pool_self_link" {
description = "self_link for default target pool"
value = "${google_compute_target_pool.compute_target_pool_default.*.self_link}"
}
Переходим теперь в папку google_cloud_platform/examples и создадим еще одну папку для проверки написанного чуда:
$ mkdir compute_target_pool && cd $_
Внутри созданной папки открываем файл:
$ vim main.tf
И вставим в него следующий код:
#
# MAINTAINER Vitaliy Natarov "vitaliy.natarov@yahoo.com"
#
terraform {
required_version = "> 0.9.0"
}
provider "google" {
#credentials = "${file("/Users/captain/.config/gcloud/creds/captain_creds.json")}"
credentials = "${file("/Users/captain/.config/gcloud/creds/terraform_creds.json")}"
project = "terraform-2018"
region = "us-east1"
}
module "compute_instance" {
source = "../../modules/compute_instance"
name = "TEST"
project_name = "terraform-2018"
number_of_instances = "2"
machine_type = "n1-highcpu-4"
service_account_scopes = ["userinfo-email", "compute-ro", "storage-ro"]
}
module "compute_health_check" {
source = "../../modules/compute_health_check"
name = "TEST"
project = "terraform-2018"
custom_name = "testhttp"
enable_compute_http_health_check = "true"
http_health_check_port = "80"
http_health_check_request_path = "/"
}
module "compute_target_pool" {
source = "../../modules/compute_target_pool"
name = "TEST"
project = "terraform-2018"
region = "us-east1"
#Use it when you want to add nodes to pool with HC
use_compute_target_pool_default = false
instances = ["${module.compute_instance.compute_instance_self_links}"]
#health_checks = ["${module.compute_health_check.http_self_link}"]
health_checks = ["testhttphcstage"]
#Use this way if you want to create default target pool for autoscaler or group manager. But, you SHOULD delete compute_instance for this case
#use_compute_target_pool_default = true
#health_checks = ["testhttphcstage"]
}
module "compute_forwarding_rule" {
source = "../../modules/compute_forwarding_rule"
name = "TEST"
project = "terraform-2018"
port_range = "80"
target = "${element(module.compute_target_pool.self_link, 0)}"
#target = "${element(module.compute_target_pool.default_pool_self_link, 0)}"
}
module "compute_firewall" {
source = "../../modules/compute_firewall"
name = "TEST"
project = "terraform-2018"
enable_all_ingress = true
enable_all_egress = true
#enable_all_ingress = false
#allow_protocol = "icmp"
#allow_ports = ["80", "443"]
}
Все уже написано и готово к использованию. Ну что, начнем тестирование. В папке с вашим плейбуком, выполняем:
$ terraform init
Этим действием я инициализирую проект. Затем, подтягиваю модуль:
$ terraform get
PS: Для обновление изменений в самом модуле, можно выполнять:
$ terraform get -update
Проверим валидацию:
$ terraform validate
Запускем прогон:
$ terraform plan
Мне вывело что все у меня хорошо и можно запускать деплой:
$ terraform apply
Как видно с вывода, — все прошло гладко! Чтобы удалить созданное творение, можно выполнить:
$ terraform destroy
Весь материал аплоаджу в github аккаунт для удобства использования:
$ git clone https://github.com/SebastianUA/terraform.git
Просмотреть список доступных зон, можно выполнив следующую команду:
$ gcloud compute zones list
Чтобы поглядеть target-pool-ы, заюзайте:
$ gcloud compute target-pools list
Или если проглядеть пул с указанным именем:
$ gcloud compute target-pools describe TARGET_POOL
Поглядеть machine type (тип инстансов), можно следующей командой:
$ gcloud compute machine-types list
Вот и все на этом. Данная статья «Работа с Google Cloud Platform (compute target pool) и Terraform в Unix/Linux» завершена.