У меня имеется следующая задача:
Необходимо синхронизировать данные между AWS MSK и on-premises Kafka или наоборот. Я нашел в интернете несколько решений. Сейчас поговорим о них:
- Использование Mirror Maker для Kafka синхронизации
- Использование языка программирования для Kafka синхронизации и написать код под данную задачу (например на Python или Java). Возможно рассмотрю вариант написания кода на питоне.
- Другие варианты которые я смогу найти или придумать реализацию (будет позже).
Приступим к решениям.
Использование Mirror Maker для Kafka синхронизации
Функция зеркального отображения Kafka (Mirror-инг) позволяет поддерживать копию существующего кластера Kafka (выполнять репликацию). На рисунке что внизу, показано, как использовать MirrorMaker для зеркалирования Kafka кластера:
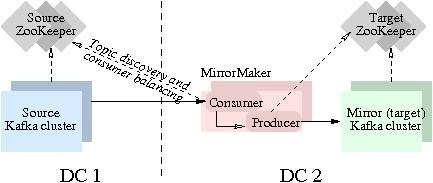
Инструмент использует consumer Kafka для получения сообщений из исходного кластера и повторно записывает эти сообщения в целевой кластер с использованием встроенного Kafka producer-а.
Как настроить mirror-ринг?
Первое что необходимо сделать, — это скачать архив с нужными скриптами, я описывал как это можно сделать в своей статье:
Может будет полезно почитать:
Настроить репликацию легко — просто запустите процесс(ы) с mirrormaker-ом.
Синхронизация данных on-premise в AWS MSK в Unix/Linux
Например если нужно засинкать данные с on-premise в AWS MSK, то нужно запустить MM так:
$ ENV="nonprod" && \
kafka-mirror-maker.sh \
--consumer.config /opt/kafka_2.12-2.2.1/kafka-onpremise_${ENV}_consumer.properties \
--num.streams 3 \
--producer.config /opt/kafka_2.12-2.2.1/mskkafkatest-cluster-${ENV}_producer.properties \
--whitelist="topic_1, topic_2" Синхронизация данных AWS MSK и on-premises Kafka в Unix/Linux
Если нужно засинкать данные с AWS MSK в on-premise, то нужно запустить MM так:
$ ENV="nonprod" && \
kafka-mirror-maker.sh \
--consumer.config /opt/kafka_2.12-2.2.1/mskkafkatest-cluster-${ENV}_consumer.properties \
--num.streams 3 \
--producer.config /opt/kafka_2.12-2.2.1/kafka-onpremise_${ENV}_producer.properties \
--whitelist="topic_1, topic_2"Где:
- ENV — Это ENV который используется.
- —consumer.config /opt/kafka_2.12-2.2.1/mskkafkatest-cluster-${ENV}_consumer.properties — Файл с настройками для консьюмера для AWS MSK.
- —consumer.config /opt/kafka_2.12-2.2.1/kafka-onpremise_${ENV}_consumer.properties — Файл с настройками для консьюмера для on-premise Kafka.
- —num.streams 3 — Выставляем количество потоков для синка.
- —producer.config /opt/kafka_2.12-2.2.1/mskkafkatest-cluster-${ENV}_producer.properties — Файл с настройками для продюсера для AWS MSK.
- —producer.config /opt/kafka_2.12-2.2.1/kafka-onpremise_${ENV}_producer.properties — Файл с настройками для продюсера для on-premise Kafka.
- —whitelist=»topic_1, topic_2″ — Лист топиков для репликации.
Рассмотрим конфиги для MM. Файл mskkafkatest-cluster-${ENV}_consumer.properties выглядит следующим образом:
# cat << EOF > ${KAFKA_PATH}/mskkafkatest-cluster-${ENV}_consumer.properties
bootstrap.servers=${AWS_MSK_BROKERS}
exclude.internal.topics=true
client.id=mirror_maker_consumer
group.id=mirror_maker_consumer
auto.offset.reset=earliest
auto.commit.enabled=false
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
security.protocol=SSL
ssl.truststore.location=${KAFKA_PATH}/mskkafkatest-cluster-${ENV}.client.truststore.jks
ssl.keystore.location=${KAFKA_PATH}/mskkafkatest-cluster-${ENV}.client.keystore.jks
ssl.keystore.password=${STOREPASS}
ssl.key.password=${KEYPASS}
ssl.protocol=TLSv1.2
ssl.enabled.protocols=TLSv1.2
ssl.endpoint.identification.algorithm=HTTPS
EOFФайл kafka-onpremise_${ENV}_consumer.properties выглядит следующим образом:
# cat << EOF > ${KAFKA_PATH}/kafka-onpremise_nonprod_consumer.properties
bootstrap.servers=${KAFKA_ONPREMISE_BROKERS}
exclude.internal.topics=true
client.id=mirror_maker_consumer
group.id=mirror_maker_consumer
auto.offset.reset=earliest
auto.commit.enabled=false
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
EOFФайл mskkafkatest-cluster-${ENV}_producer.properties выглядит следующим образом:
# cat << EOF > ${KAFKA_PATH}/mskkafkatest-cluster-${ENV}_producer.properties
bootstrap.servers=${AWS_MSK_BROKERS}
acks=-1
batch.size=8196
client.id=mirror_maker_producer
retries=Int.MaxValue
bock.on.buffer.full=true
max.in.flight.requests.per.connection=1
security.protocol=SSL
ssl.truststore.location=${KAFKA_PATH}/mskkafkatest-cluster-${ENV}.client.truststore.jks
ssl.keystore.location=${KAFKA_PATH}/mskkafkatest-cluster-${ENV}.client.keystore.jks
ssl.keystore.password=${STOREPASS}
ssl.key.password=${KEYPASS}
ssl.protocol=TLSv1.2
ssl.enabled.protocols=TLSv1.2
ssl.endpoint.identification.algorithm=HTTPS
EOFФайл kafka-onpremise_${ENV}_producer.properties выглядит следующим образом:
# cat << EOF > ${KAFKA_PATH}/kafka-onpremise_nonprod_producer.properties
bootstrap.servers=${KAFKA_ONPREMISE_BROKERS}
acks=-1
batch.size=8196
client.id=mirror_maker_producer
retries=Int.MaxValue
bock.on.buffer.full=true
max.in.flight.requests.per.connection=1
EOFНе очень и сложно выполнить запуск. Разработчики рекомендуют запускать MirrorMaker на целевом кластере т.к летенси будет меньше.
Можно использовать и другие параметры для запуска, например:
- —blacklist — Указать лист топиков которые стоит заблокировать ( не синкать).
Другие добавлю позже, если будет необходимость их использования. Для себя использовал AWS EC2 машинку с t2.xlarge шейпами. В идеале — сделать Helm chart со всем необходимым и задеплоить это решение в Kubernetes. Но об этом, немного позже.
Проверка работы mirror-а
Например, если выполнить следующую команду:
# kafka-consumer-offset-checker.sh \
--group KafkaMirror \
--zkconnect dc1-zookeeper:2181 \
--topic test-topic
Group Topic Pid Offset logSize Lag Owner
KafkaMirror test-topic 0 5 5 0 none
KafkaMirror test-topic 1 3 4 1 none
KafkaMirror test-topic 2 6 9 3 noneИнструмент проверки полезен для оценки того, насколько хорошо выполнилось зеркалирование между кластерами. Если топик не указан, то будет выводить информацию по всем топикам в данной consumer группе.
Нашел в интернете запуск ММ еще одним способом:
# kafka-run-class.sh kafka.tools.MirrorMaker \
--consumer.config sourceCluster1Consumer.config \
--consumer.config sourceCluster2Consumer.config \
--num.streams 2 \
--producer.config targetClusterProducer.config \
--whitelist=".*"Тестировал, работает нормально.
Настройка производительности MirrorMaker
Что можно потюнить?
Увеличение пропускной способности при высокой задержке
Я столкнулся с тремя основными проблемами, влияющими на пропускную способность: плохое сжатие, недостаточное количество пакетов и низкий параллелизм.
Изменим данный параметр на:
linger.ms = 15000Включить сжатие
Меньшие сообщения отправляются быстрее, чем большие, поэтому уменьшение размера больших сообщений, как правило, ускоряет их отправку. Это также экономит на пропускной способности. Важно отметить, что сжатие более эффективно для больших сообщений, поскольку существует больше возможности для поиска повторяющихся фрагментов. Изменим данный параметр:
compression.type = gzipДефолтное значение — none. Результатом стало значительное уменьшение количества байтов, передаваемых из MirrorMaker в другой Kafka кластер. Это также уменьшило объем дискового пространства, необходимого для хранения сообщений, поскольку Kafka хранит их в своих сжатых пакетах.
Выставляем batches для сообщений
Первоначально, я увеличил batch.size для MirrorMaker со значения по умолчанию с 16384 до 1000000 байт, что соответствует размеру темы по умолчанию max.message.bytes. Проблема этого подхода заключается в том, что Kafka заполняет пакет сообщений не на основе общего размера несжатых сообщений, а скорее на предполагаемом сжатом размере сообщений. Так что может случиться так, что степень сжатия данных иногда выше расчетного, что приводит к тому, что размер сжатого пакета становится больше, чем размер раздела max.message.bytes. Это приведет к тому, что пакет сообщений будет отклонен broker-ом. Когда это происходит, брокер регистрирует исключение kafka.common.MessageSizeTooLargeException. MirrorMaker либо отбросит сообщение, либо прекратит работу в зависимости от того, как оно настроено.
Первая часть решения состояла в том, чтобы убедиться, что продюсер MirrorMaker использует max.request.size = topic max.message.bytes. Кроме того, producer max.request.size = broker message.max.bytes. Это гарантирует, что регулярные (не пакетированные) сообщения, считанные из конечного кластера Kafka, могут быть успешно отправлены в кластер агрегатора Kafka.
Вторая часть решения заключается в том, чтобы обеспечить batch.size producer-а <«ожидаемая степень сжатия» * max.request.size. Продюсер в Kafka будет динамически обновлять ожидаемую степень сжатия на основе степени сжатия предыдущих сообщений. Таким образом, чтобы избежать сжатия сжатого пакета, превышающего max.message.bytes, выберите batch.size, который меньше max.message.bytes * «максимальная степень сжатия». Таким образом, действительно консервативное значение будет 20: 1 или 0,05. Это зависит от входных сообщений, но теоретический максимум может быть 1000: 1, и в этот момент вы должны сомневаться в ценности отправляемых данных, поскольку они почти полностью избыточны. Producer Kafka сообщает о средней степени сжатия, которая может быть хорошей отправной точкой, но наиболее точной будет полная гистограмма всех партий. В моем случае я использовал (0,05 * batch.size = 50000), поскольку мы отражаем различные темы и не имеем прямого контроля над содержимым сообщения:
batch.size = 50000Выставляем память буфера для всех разделов (партиций)
Продюсер Kafka собирает сообщения в пакеты в один общий блок памяти. Блок разделен на куски, каждый из которых имеет размер batch.size. Когда сообщения отправляются продюсеру, они добавляются в новый пакет или в существующий, если он есть. Если количество разделов на стороне агрегированного кластера намного больше, чем количество пакетов, которые могут поместиться в буфере, то вызов producer.send() будет блокироваться, пока один из них не станет доступным. Это может оказать существенное негативное влияние на производительность:
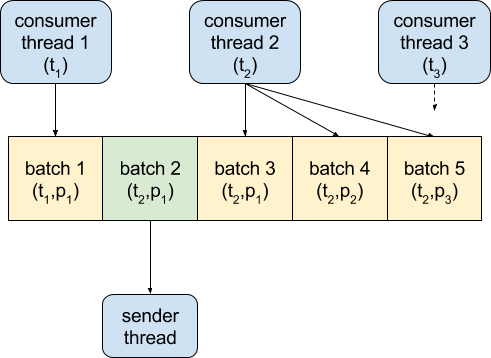
Решение состояло в том, чтобы установить продюсеру buffer.size = «общее количество агрегированных кластерных разделов» * batch.size. Это приводит к тому, что процесс MirrorMaker выделяет большой статический кусок памяти, но потребительские потоки не блокируются в ожидании пространства в буфере производителя и могут использовать данные так быстро, как только они становятся доступными. Производитель может сжимать и отправлять полные партии, что максимизирует общую пропускную способность:
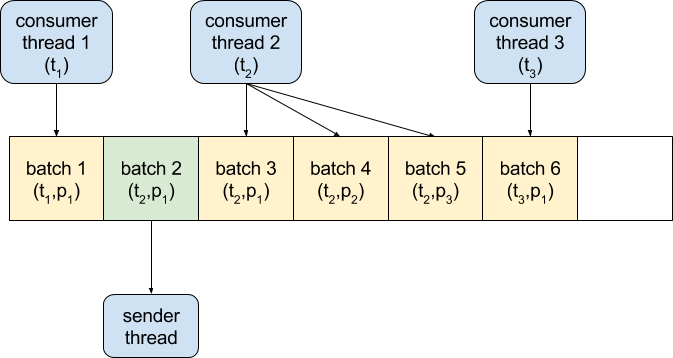
Итог будет выглядеть:
Можно потюнить некоторые параметры чтобы ММ работал быстрей, например, можно к MirrorMaker producer-у добавить следующие настройки:
batch.size = 50000
buffer.memory = 2000000000
compression.type = gzip
linger.ms = 15000
max.request.size = 1000000Вот и все.
Использование языка программирования для Kafka синхронизации
Пока не будет примеров, т.к я не очень хочу изобретать велосипед. Но чисто теоретически ( та и практически), можно написать утилиту которая будет выполнять чтение с одного стрима/топика и писать в другой.
Для Python есть несколько готовых либ, можно заюзать:
- kafka-python
- aiokafka
- pykafka
- confluent-kafka-python
Вот и все, статья «Синхронизация данных AWS MSK и on-premises Kafka в Unix/Linux» завершена.